La classification des données

Une activité importante de la cybersécurité concerne la classification de la donnée.
En effet, l'information est souvent au cœur de la stratégie d'une entreprise : que ce soit la recette secrète de Coca Cola qui est un enjeu important pour la stratégie et l'image de marque de l'Entreprise, les travaux de recherches sur le vaccin anti-covid de Pfizer qui est capital pour l'aspect financier, ou encore les données temps réel de la puissance neutronique d'un réacteur nucléaire qui a un impact sur la sûreté, il est primordial de protéger ces informations et de travailler sur les aspects de confidentialité.
Les biens essentiels
On voit donc que ces informations, qui peuvent également être des processus ou plus généralement des biens ou des ressources ont une valeur pour l'Entreprise et doivent être protégés à hauteur des enjeux. On appelle cela des Biens Essentiels ou des Actifs.
Et parmi les informations que l'on retrouve en Entreprise,, certaines se doivent d'être protégées plus que d'autres, telles que les données sensibles.
On appelle donnée sensible toute information non publique ou non déclassifiée.
On retrouve par exemple les données personnelles, les données de santé ou encore les données propriétaires comme les brevets, les secrets, les copyrights.
Les 3 formes principales de l'information
Lorsque l'on pense à la confidentialité des données, on pense généralement aux documents numériques : les notes, fichiers textes, les présentations, les normes, etc. Mais il existe deux autres types de formes qu'il est nécessaire de prendre en considération lorsqu'il s'agit de protéger la donnée : la forme orale et la forme matérielle.
La façon la plus simple de partager de l'information consiste à échanger de vive voix avec votre ou vos interlocuteurs. Que ce soit lors d'une visioconférence, par téléphone ou lors d'échanges avec vos collègues en face à face, il est important de considérer le type de données échangées et de se poser la question suivante : est-ce que ce lieu est approprié pour échanger ?
En effet, imaginez-vous parler d'informations classifiées dans le train ou dans un bar ? Il pourrait y avoir des oreilles indiscrètes. Ou bien encore parler d'informations confidentielles et hautement stratégiques lors d'une visioconférence sur Zoom (qui a subi plusieurs revers concernant la confidentialité avec la capacité des attaquants à pouvoir s'introduire dans des réunions sans y être conviés) ? Non et pourtant cela arrive tous les jours...
La dernière forme de l'information est matérielle ou physique : on y retrouve les impressions, les informations notées sur des tableaux, les notes et autres documents ou encore les post-it. N'oubliez pas que ces données sont une mine d'or pour les attaquants et qu'il suffit parfois d'aller fouiller une poubelle à la sortie de l'Entreprise pour récupérer de nombreuses données.
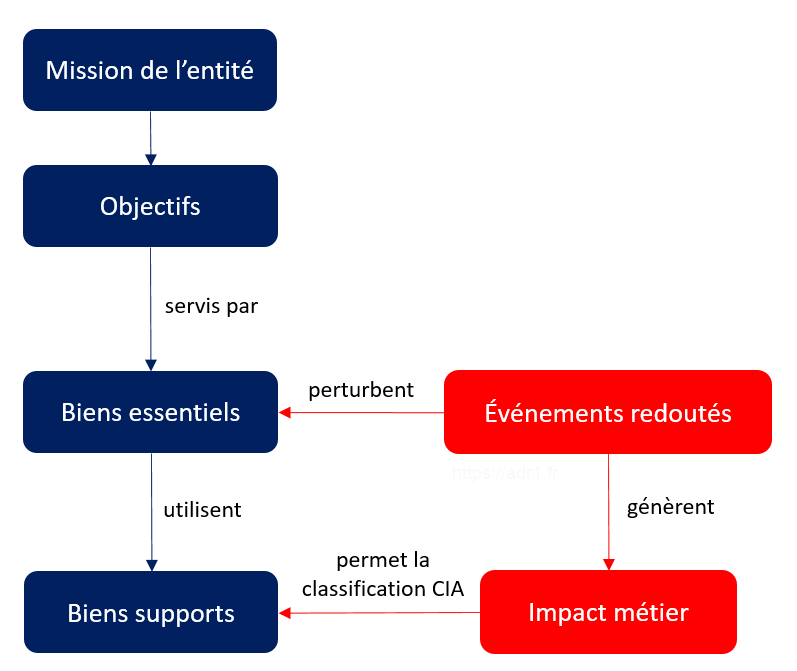
Le cycle de vie de la donnée
Créer la donnée
La démarche de classification consiste en quatre étapes :
• Identifier
• Classifier
• Mettre en œuvre les exigences
• Auditer
Identifier
L'identification est la base de la classification. Sans vision complète des informations traitées par l'Entreprise, vous ne pouvez pas déterminer les impacts d'une fuite de données. La première étape consiste donc à identifier les familles d'informations en fonction des processus de l'Entreprise si ils existent ou simplement en fonction de la typologie des usages (exemple : les données RH, les données industrielles, les données IT, etc.)
Cette action est à réaliser par le référent ou le sachant du domaine, ou à défaut par le manager avec l'appui du RSSI, RSP ou I2L.
Classifier
Une fois que l'on a une vision globale et précise des données traitées par l'Entreprise, il est nécessaire de réaliser une analyse de risque cybersécurité afin de déterminer le niveau de risque et les critères CIA.
 Adrien
Adrien
La classification est souvent représentée sous la forme suivante :
- C = 0 : public
- C = 1 : interne (à l'Entreprise)
- C = 2 : restreint (à une population identifiée)
- C = 3 : confidentiel
Mettre en œuvre les exigences
Il est ensuite nécessaire de mettre en œuvre l'ensemble des exigences relatives au niveau de classification identifié. Bien évidemment qu'un niveau plus élevé de confidentialité requiert un nombre d'exigences plus important avec généralement une mise en œuvre plus complexe.
Auditer
La mise en œuvre d'exigences, quel qu'elles soient nécessitent obligatoirement la réalisation d'évaluation afin de s'assurer que les règles sont comprises et respectées.
Chaque nouvelle création de familles d'information doit passer par ces étapes.
Utiliser et partager la donnée
En fonction du caractère confidentiel de la donnée utilisée, il peut être nécessaire de mettre en œuvre des techniques de protection de l'information.
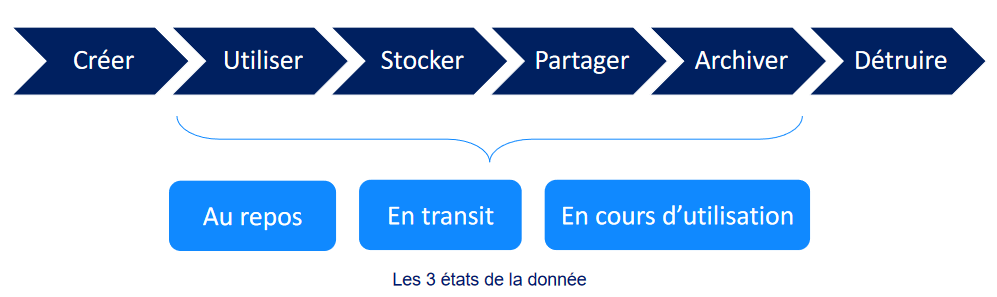
Nous avons vu précédemment que l'information pouvait être sous 3 états : au repos, en transit ou en cours d'utilisation. Pour chaque état, il existe des méthodes de protection de la donnée.
Au repos
Lorsque l'information est au repos, elle est généralement stockée pour du court terme avec une utilisation possible ou pour du long terme pour des questions d'archivage.
Il est possible de stocker la donnée de manière chiffrée directement au niveau des bases données, ou bien à l'aide de conteneurs sécurisés ou encore physiquement grâce à des supports qui intègrent du chiffrement de surface.
En transit
L'information peut également être en mouvement entre le client, le serveur et la base de donnée par exemple. Pour cela, il existe des protocoles capables de créer des canaux sécurisés. On retrouve par exemple HTTPS qui intègre du TLS ou encore IPSec.
Adrien
En utilisation
L'information doit également être protégée lorsqu'elle est en cours d'utilisation grâce par exemple à des systèmes qui vérifient l'intégrité de la mémoire. Si on reprend l'exemple du jeune cadre dynamique qui lit un document PDF sur son PC portable, l'utilisation d'un filtre de confidentialité sur l'écran de son PC peut-être un moyen de limiter les regards indiscrets (et vous n'imaginez pas tout ce que l'on peut apprendre simplement en regardant l'écran de son voisin de voyage…)
Enfin, il existe des matériels dédiés à la surveillance tels que les DLP - Data Leak Prevention dont c'est le rôle explicite de surveiller les données qui transitent entre l'Entreprise et internet de manière à protéger contre l'exfiltration de données ou les CASB - Cloud Access Security Broker qui permettent de contrôler les accès ou monitorer les activités.
Archiver la donnée
Une règle spécifique est applicable à l'archivage. En effet, l'archivage permet entre autre de pouvoir remonter dans le temps afin de récupérer l'historique d'une donnée, ou bien à pouvoir sécuriser une donnée importante contre la perte ou la destruction (coucou les ransomware).
Et quand il s'agit de protéger la donnée, il existe la règle du backup 3-2-1.
- Réaliser 3 copies
- Utiliser 2 supports différents
- Stocker dans 1 location distante

Pourquoi 3 copies ?
C'est très simple : la première est généralement réalisée sur le serveur concerné, la deuxième est réalisée sur un serveur de sauvegarde et la dernière est réalisée sur un serveur distant.
Pourquoi 2 supports différents ?
Pour éviter qu'on appelle le risque de mode commun ; c’est-à-dire le risque de panne générique. Imaginez que vous mettiez vos données sur 2 disques dur de marque western digital. Pas de chance cette série est défaillante et au bout de 1000 heures d'utilisation le disque tombe en panne, vous vous retrouvez alors sans aucune donnée (je précise que je n'ai jamais eu aucun soucis avec des disques western digital :D)
Pourquoi 1 localisation distante ?
Si je reprends mon exemple précédent, vos disques durs sont localisés dans votre bureau et pas de chance pour vous, il prend feu : vous perdez alors vos deux sauvegardes. Une localisation distante permet de limiter le risque.
Détruire la donnée
Chaque donnée doit avoir une date de "péremption" qui précise que la donnée n'est plus utile et peut être détruite. En fonction de la confidentialité de la donnée, différentes techniques d'effacement sécurisés peuvent être utilisées.
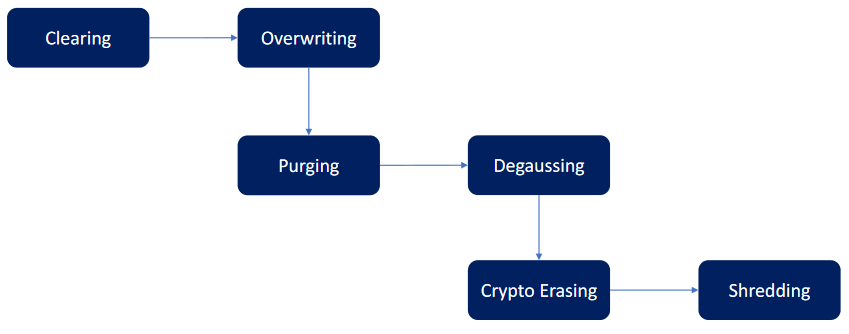
Par ordre d'efficacité :
- Clearing : formatage rapide de votre support. Ne supprime pas les données.
- Overwriting : réécrire sur les données existantes. Ne supprime pas entièrement les données
- Purging : effectuer plusieurs passages de réécriture des données en alternant les techniques. Ne supprime pas entièrement les données mais reste très efficace
- Degaussing : démagnétiser un disque dur. Ne fonctionne que sur les HDD et ne supprime pas entièrement les données
- Crypto Erasing : supprimer la clé de déchiffrement. Risque important d'être en capacité de déchiffrer les données un jour (vulnérabilité de l'algorithme, brute force, etc.)
- Shredding : destruction totale du support. Selon la technique employée, la donnée peut être recouvrée.
En bref
La classification de la donnée est nécessaire dans toute organisation et doit passer par l'identification des données traitées et des utilisateurs, la réalisation d'une analyse de risque basée sur les critères de disponibilité, confidentialité et intégrité, la mise en oeuvre des exigences associées et enfin par des audits réguliers.
Il est important de considérer l'ensemble des formes (numériques, orales et physiques) et des états de la donnée (au repos, en transit, en cours d'utilisation), notamment lors des déplacements à l'extérieur de l'Entreprise.
💌 Vous aimez l'article que vous avez lu ?
Pensez à vous inscrire et découvrez d'autres articles seulement visibles pour la communauté ! Et en bonus, un nouvel article chaque dimanche ! 😀